What progress have you made since your last update?
tl;dr: I now have a decent baseline model architecture, a mostly-validated mini-language for it to learn, and a good pipeline for running experiments. This is my first update. Project started 13 July, 9 days ago.
Code on GitHub: z0u/sca2, reports: z0u.github.io/sca2.
Started work on D2.1. To recap: This deliverable is about anchoring concrete concepts in a transformer. As described in the proposal, the domain we’re focusing on is color mixing. The grammar of these experiments is "a + b = mix(a, b)", e.g. "red + blue = purple". The model is trained to predict the answers of equations like that. In D2.1, I hope to demonstrate that the colors can be anchored (and perhaps intervened on, although that might wait until D2.2).
Science: I ran four experiments to establish a baseline for anchoring: I wanted to get a feel for how the models behave with this mini language. The experiments explore which model size is appropriate (width and number of layers), and which vocabularies can be used for this task: named colors only ("red"), or also RGB hex codes ("#f00"); how many colors are needed, and what kinds of tokenization work (word- or character-level). So far, all of these experiments have been un-anchored.
Findings: a 64x4 nGPT-like transformer learns the mixing task; both word- and character-level tokenization work (character-level slightly less well); and 216 colors (6 levels of red, green, and blue) works best. I thought that the hex codes were confusing the model on one sub-task, but actually I think it's just that there weren't enough named colors to decode to. For details, see Appendix A (below) and the linked reports.
Engineering: Some infrastructure work for experiment tooling (e.g. for Claude to use to write an monitor experiment progress) and report-publishing. More work on this happened just before starting the project; see Appendix B (below).
Ops: I engaged an accountant and set up a business entity to receive funds.
What are your next steps?
Continue on D2.1. I would like to do one more experiment with both named colors and hex codes, because I think having multiple surface forms could shield me a little from the trap of the transformer learning something trivial.
More importantly: anchor a single concept in the residual stream. I'll start with anchoring "red", as in M1, using similar regularization terms and sparse, noisy labels. And I'll measure whether the anchor worked by probing the residual stream.
I also plan to change my workflow a little. I've had Claude running my experiments and writing the first draft of the reports in one go. This let me run the experiments quickly, but I found I had to spend a long time editing the reports. I still want to have Claude write and run each experiment, but I might have it produce only a skeleton of the report that I can then fill in.
Is there anything others could help you with?
I would love feedback from a researcher about the direction this is going. Have I fallen into any traps with these analyses? Engaging fully with the reports would be time consuming so I'm happy to discuss if that's easier. I plan to seek feedback directly from some people.
Appendix A. D2.1 experiment summaries
M2/Ex-2.1.1: Character-level nGPT (6 sizes), trained on named colors and hex codes (so some of the colors have two surface forms for the same concept). The larger models learnt the relationships and could solve equations like "r·e·d·+·b·l·u·e·=·p·u·r·p·l·e", and "o·r·a·n·g·e·+·#·2·c·7·=·#·9·a·4", but could not give named color answers for equations it hadn’t seen during training ("named_unseen" in the figure below).

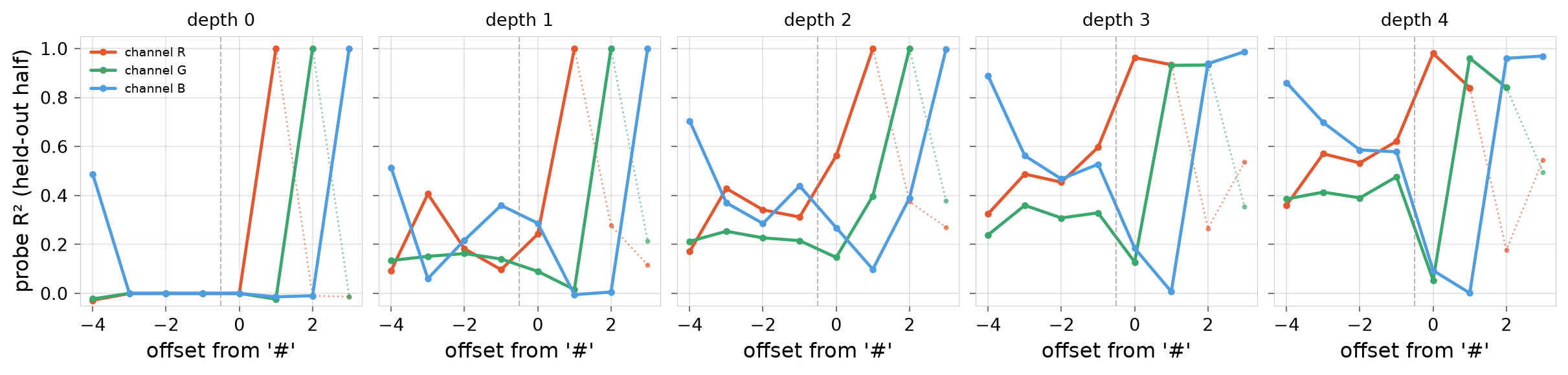
M2/Ex-2.1.2: Added reverse-mapping expressions like "#·f·0·0·=·r·e·d" to see if that would teach the model to give named answers for equations it hadn’t seen before, but it didn’t work. Per-channel probes revealed that when the model is outputting hex, it computes each channel just-in-time (note the sequential red, green, and blue spikes in the figure below).
M2/Ex-2.1.3: Switched from character-level to word-level embeddings, without hex codes, to prevent the model from doing per-channel mixing. Sequences like "red·+·blue·=·purple" (~5 tokens). Tested vocabulary sizes: 27, 64, 216, and 4096 colors. This worked well: with the 216-color grid, the model performed almost perfectly on held-out equations. Since this vocabulary has one token per color, a probe can find the RGB color cube in the embedding layer (shown below).
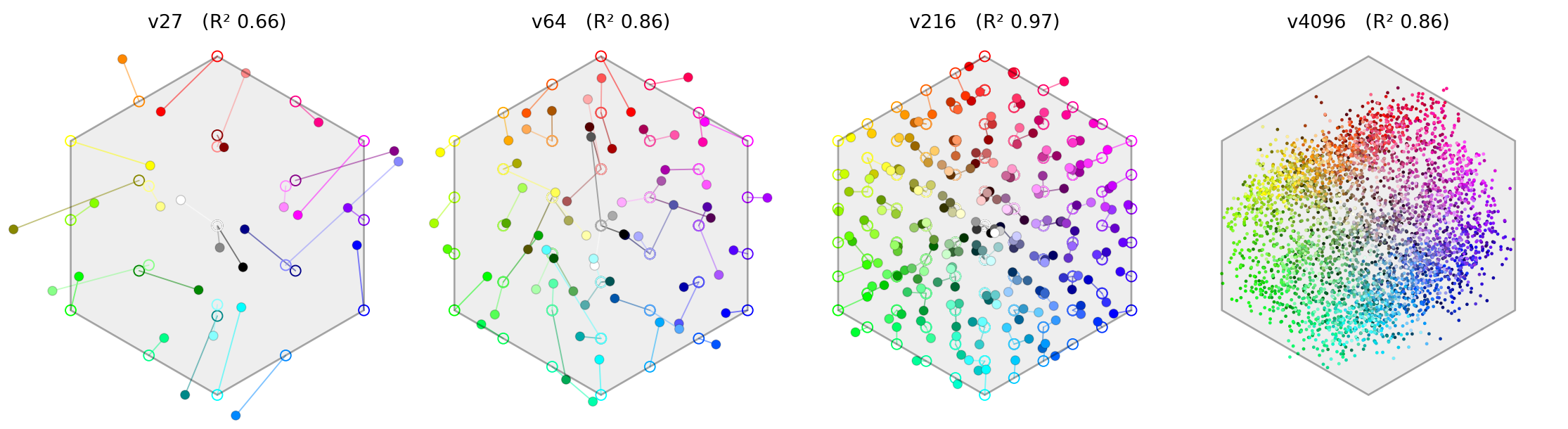
M2/Ex-2.1.4: A one-token-per-concept language isn’t a good test of a transformer (the geometry is even available at layer 0!), so this experiment splits them up again. There are no hex codes (like the previous experiment), but we now have multiple tokens per color. Sequences like "v·s·q·v·+·t·e·f·q·=·m·n·i·h"; the color names are random (but stable) to prevent the model from learning other associations (like hex did). These models learnt well from the 216-color grid, with a probe finding that the answer is decodable as RGB at the final layer.
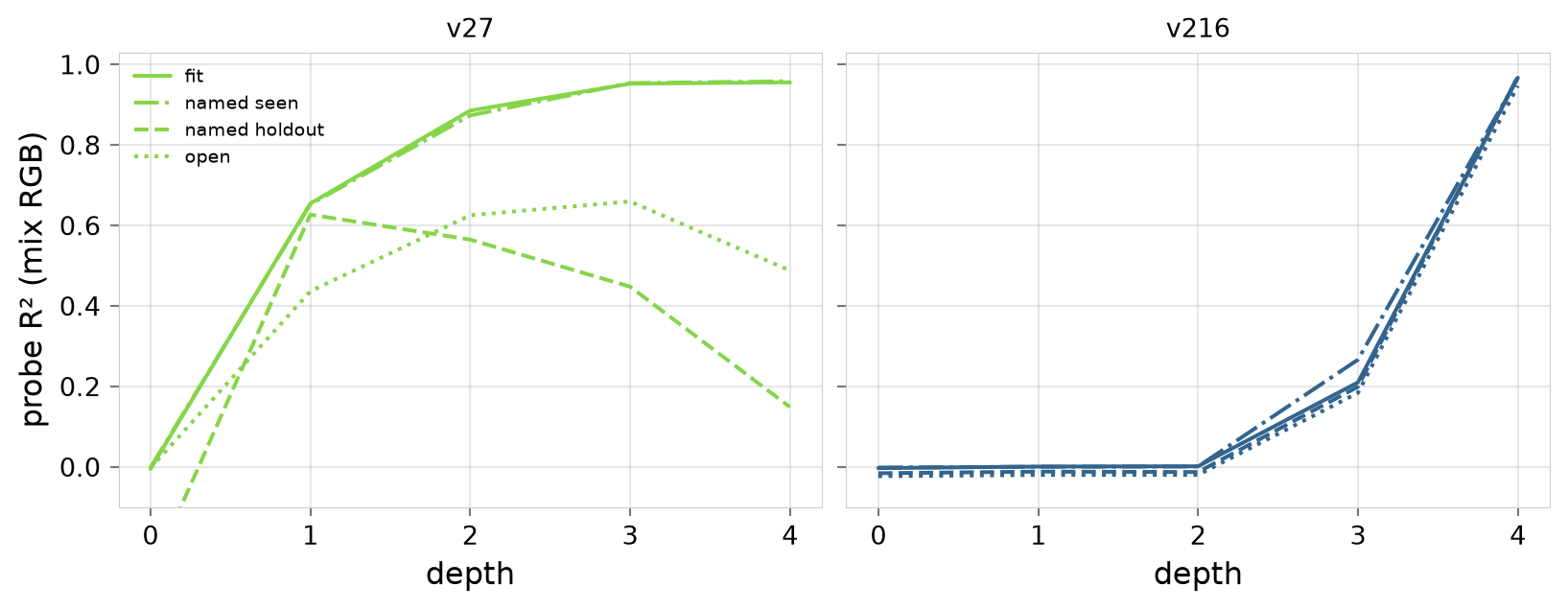
The 27-color grid did not work for held-out equations, and further analysis found that it can't: it's just too coarse to properly express these equations (see report for details).
Appendix B. Iteration 0 (prep)
Mostly engineering tasks, and a few experiments. Done before my nominal start date of 13 July.
Infra setup: Cloned my template repo and set it up for publishing artifacts to Hugging Face.
Ported an experiment from M1 (deleting red from a 5D autoencoder) to JAX and ran it on Modal as an end-to-end test of the infrastructure (report 1). The SCA paper had left the large variance across seeds as "future work", so I ran a few extra experiments; turns out it’s solved by defining a target to redirect to when deleting a concept (report 2, report 3, report 4).
The M1 experiments used spherical (unit norm) embeddings, and the paper suggested nGPT as the initial LLM architecture to use for SCA. Since I intend to use a simplified version of that architecture in this milestone (M2), I ran a small width × depth sweep over it on natural language data, and (after some bug fixes) it performed well (report).
