Edit (14 Nov 2025): While the original target was not reached within Manifund, I received an external grant that complements these funds and reaches the target. Hence, I'm lowering the target here to avoid more donations. Thank you!
Project summary
While Large Language Model (LLM)-based agents have demonstrated remarkable capabilities, they continue to face substantial safety challenges. This research investigates the integration of PDDL-based symbolic planning with LLMs as a potential solution to these issues. By leveraging the ability of LLMs to translate natural language instructions into PDDL formal specifications, we enable symbolic planning algorithms to enforce safety constraints during the agent’s execution.
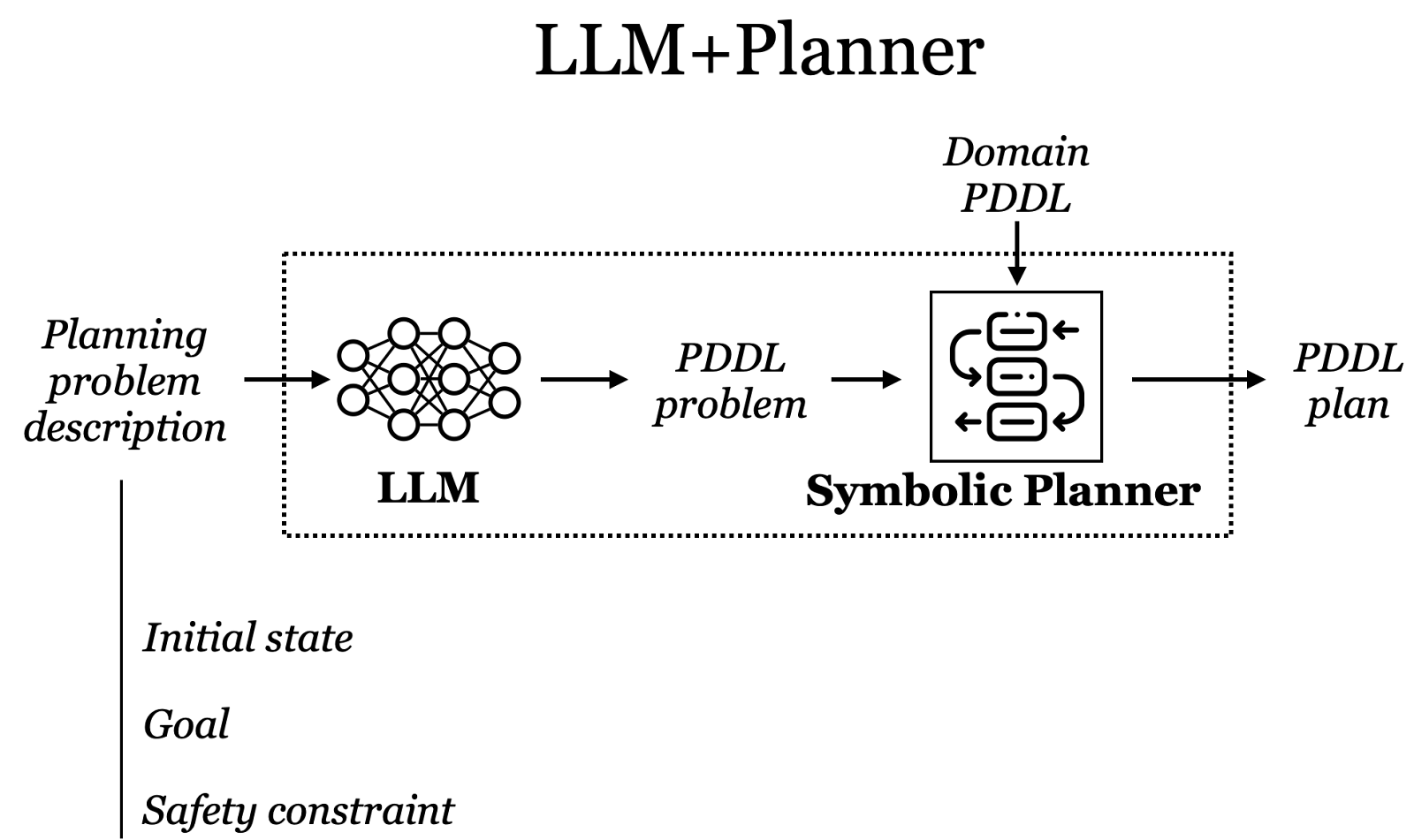
Preliminary experimental results suggest that this approach ensures safety even under severe input perturbations and adversarial attacks. To better understand the scope and reliability of these early findings, we are developing a benchmark to systematically evaluate our approach across a broad set of problem instances and diverse state-of-the-art LLMs.
This project originated as part of a PIBBSS research fellowship. Our PIBBSS final report provides a comprehensive technical description, along with data and analysis of our preliminary experimental results.
Minimum funding for valuable experiments: ~1500 USD,
Stage 1 funding: ~5000 USD (SotA instruction-tuned LLMs),
Stage 2 funding: ~9000 (SotA reasoning LLMs).
What are this project's goals? How will you achieve them?
The goal of this research is to lay the foundation for deploying LLM-based agents with guaranteed safety in real-world applications by leveraging formal reasoning through automated symbolic planners. Specifically, the funding we seek will support the establishment of robust experimental results for an initial version of our approach. More broadly, we aim at evaluating how well current LLMs / LLM-agents do at safe planning as a goal in itself, so that we better understand the risks of deploying such systems in safety-critical agentic applications.
We will achieve this by:
Developing a tool to systematically generate planning problem instances of varying sizes and incorporating diverse safety constraints. This will create SafePlanBench, a new benchmark for evaluating how well LLM agents do at safe planning.
Evaluating our approach against this benchmark. Since the choice of LLM is a critical factor, we will perform evaluations across multiple state-of-the-art LLMs to assess the effectiveness and generalizability of our approach.
The baselines we plan to compare against are SotA instruction-tuned LLMs like GPT-4o and Claude 3.5, and reasoning LLMs like o1.
How will this funding be used?
The funds will be allocated for API credits to run closed-source models and for computational resources to execute open-source models.
See our Cost estimation spreadsheet. We estimate
~5000 USD for evaluating SotA instruction-tuned LLMs, and
~9000 USD for evaluating SotA reasoning LLMs.
We estimate that executing a minimal valuable subset of the experiments would cost ~1500 USD.
Who is on your team? What's your track record on similar projects?
Tan Zhi Xuan is a 6th year PhD student in the MIT Probabilistic Computing Project and Computational Cognitive Science lab, advised by Vikash Mansinghka and Josh Tenenbaum. She is a board member of PIBBSS and serves as a mentor for the PIBBSS Summer Fellowship. Xuan is one of the authors of the position paper Towards Guaranteed Safe AI, and her research has been published in NeurIPS, AAAI, Nature Human Behaviour, among others.
Agustín Martinez Suñé holds a PhD in Computer Science from the University of Buenos Aires. In the summer of 2024, he was a PIBBSS Research Fellow and will soon begin a Postdoctoral Research position in the Oxford Control and Verification group at the University of Oxford, advised by Alessandro Abate. His research has been published in FM (Formal Methods Europe) and ICTAC (Theoretical Aspects of Computing), among others.
What are the most likely causes and outcomes if this project fails?
We consider the project a failure if we cannot conduct a robust and systematic evaluation of the PDDL-based approach that provides experimental data on its ability to ensure the safety of LLM-based agents. However, obtaining experimental results that do not support our hypothesis—that our approach enhances safety—will not be considered a failure. Rather, such results will be valuable for refining and recalibrating the approach.
The primary risks to the project's success include technical challenges in developing and executing the benchmark, as well as the potential creation of a benchmark that is not sufficiently diverse or representative to evaluate the safety of LLM-based agents effectively. The experimental framework developed during the PIBBSS fellowship has already demonstrated the feasibility of our experimental evaluation with a smaller benchmark. Our current strategy for automating the random generation of problem instances aims to establish a benchmark that is auditable, reproducible, and diverse.
How much money have you raised in the last 12 months, and from where?
Between early June and early September, Agustín was funded by PIBBSS to perform a summer research fellowship (4,000 USD/ month for 3 months).